Model analityczny do identyfikacji powtarzalnych wzorców cenowych na wykresach giełdowych i nie tylko. Analizuje dane rynkowe w czasie rzeczywistym, identyfikuje pierwotne sekwencje cenowe i porównuje je z kolejnymi, wykorzystując dynamiczne widełki tolerancji. Umożliwia wizualizację wykrytych wzorców oraz dostarcza informacji o ich częstotliwości, oferując narzędzie do poparcia spekulacji.
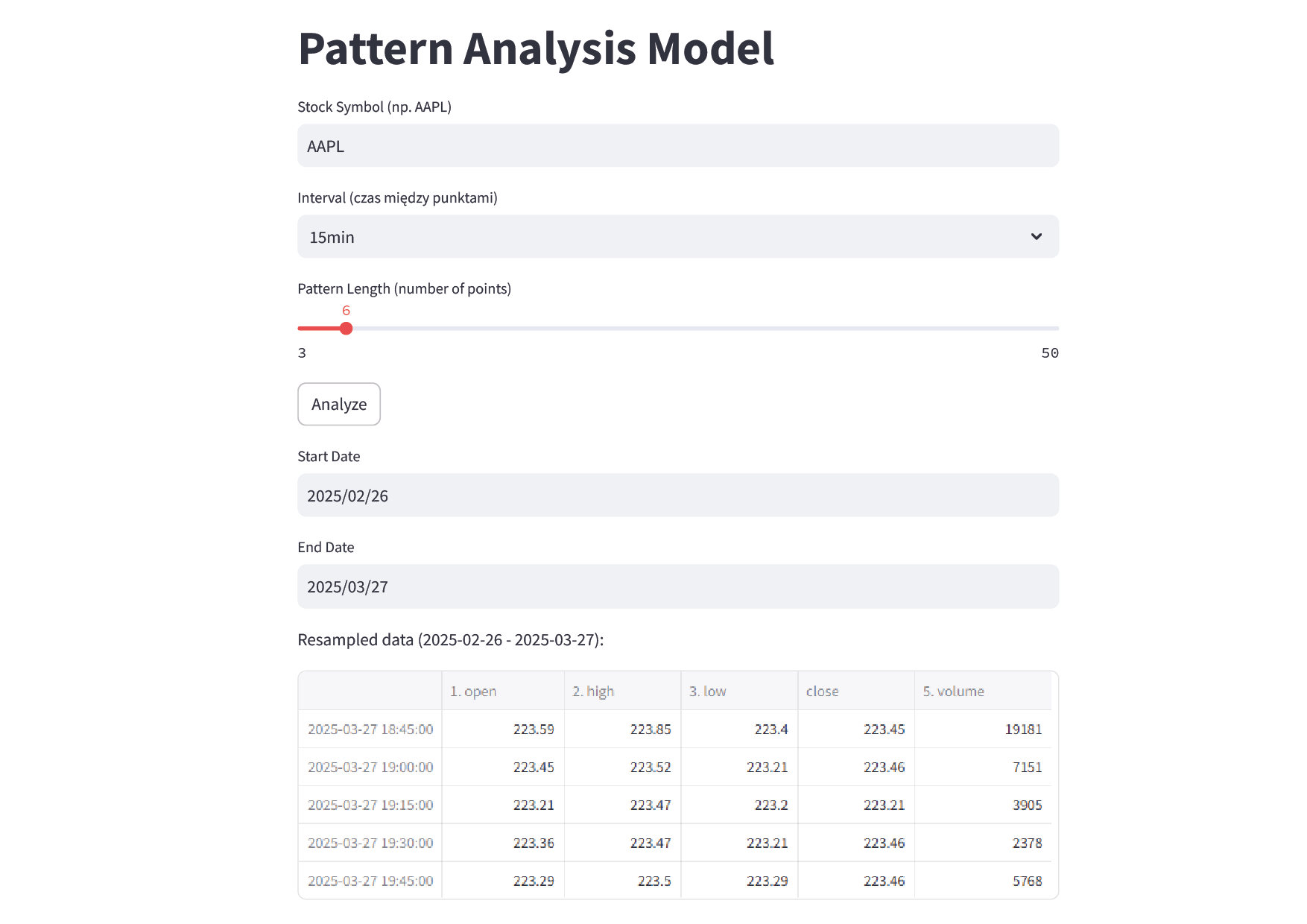
Dane
Manualnie wprowadzane dane:
Zbiór wartości i jego czas „od – do”. Pobierany z wybranej biblioteki zbiorów;
Interwał czasowy między wartościami/punktami w zbiorze. *Co od razu wyznaczy z ilu wartości składać się będzie cały zbiór;
Z ilu punktów/wartości będzie się składać pojedynczy okres.
UI z bety 0.2
Proces
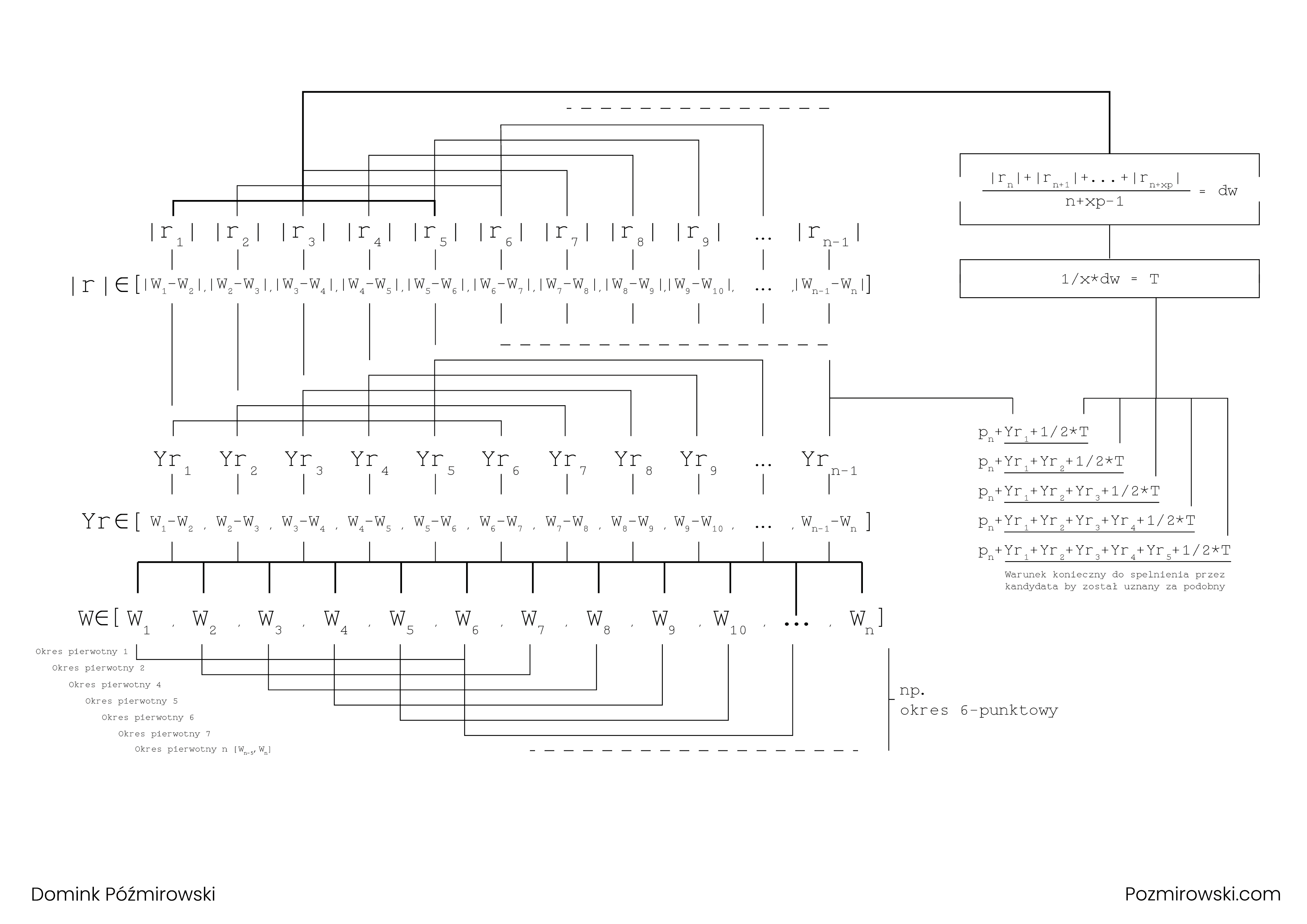
Model traktuje każdy ciąg (x wprowadzonej ilości punktów) wartości jako okres pierwotny;
Liczy ciąg różnic do każdego okresu pierwotnego;
Ciąg różnic okresu pierwotnego wyznacza ścieżkę kandydata na okres podobny do pierwotnego [Yr1, Yr2, …, Yrn];
Średnia arytmetyczna z wartości bezwzględnej różnic w okresie pierwotnym stanowi jego dynamikę ( „dw” );
1/x*dw jest wzorem na tolerancję ( T ) względem każdego punktu w okresie kandydującym, gdzie x stanowi wysokość tolerancji a jego testowa sugerowana wartość to 10/9;
Określany jest warunek klasyfikacji okresów następujących jako podobne do pierwotnego za pomocą:
pn+Yr1+1/2*Tdla pierwszego punktu
pn+Yr1+Yr2+1/2*Tdla drugiego punktu
pn+Yr1+Yr2+Yr3+1/2*Tdla trzeciego punktu
… dla … punktu kandydat
( ilość punktów wybrana manualnie przy określaniu ilości wartości w okresie pierwotnym);
Jeśli warunek jest spełniony badany okres zostaje uznany za podobny do pierwotnego.
Schemat powyżej opisanego działania
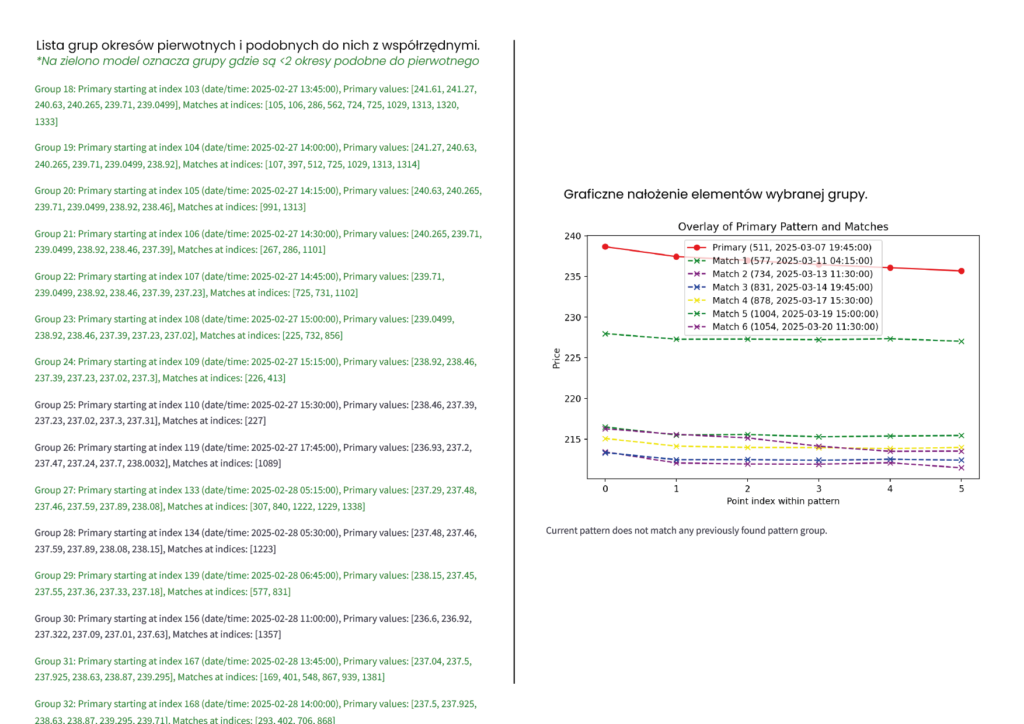
Wynik
Model wyświetla użytkownikowi tekstowo oraz graficznie gdzie, kiedy i ile okresów podobnych wystąpiło do jakiego i kiedy występującego okresu pierwotnego.